Geometric-aware RGB-D representation learning for hand-object reconstruction
|
|
|
|
|
|
|
|
|
|
|
Abstract
Reconstructing hand-object interaction from single images, crucial for interactive applications, is challenging due to the diversity of hand-object poses and shapes. Depth maps effectively complement RGB data in understanding these interactions geometrically within challenging scenes. However, most existing methods do not fully utilize the potential benefits of RGB-D information fused at different feature levels for reconstruction, limiting their capability to capture the geometric details of hand-object interaction. To address this, we propose an implicit geometric-aware RGB-D representation learning approach using adaptive bidirectional RGB-D feature fusion (ABF) and geometric Fourier feature encoding (GFFE). This method innovatively leverages the hierarchical and complementary high-level features of RGB-D information to enhance the neural implicit representations of hand-object interaction during the feature extraction and encoding stages of RGB-D data. Initially, a two-stream RGB-point cloud encoder, combining CNN and Transformer architectures, extracts appearance and geometric information from RGB and point cloud data. Subsequently, ABF fuses this information, generating dense RGB-D features by leveraging the complementary of appearance and geometric features along with the varying sensitivities of different layers. Finally, GFFE encodes 3D query points to precisely capture and learn the geometric details of hand-object interaction. Experimental results on the real-world DexYCB benchmark demonstrated that the proposed method outperformed the existing method by 8.31% and 9.51% in object shape error (Ose) and hand shape error (Hse), achieving 1.467 cm^2 and 0.2751 cm^2, respectively.
Interactive 3D Demo
We present an interactive demo to show our reconstructed 3D model. Our model takes input the RGB-D image and generates the output by decoding predicted signed distance fields. Here are demo instructions:





 |
 |
 |
 |
 |
 |
Method
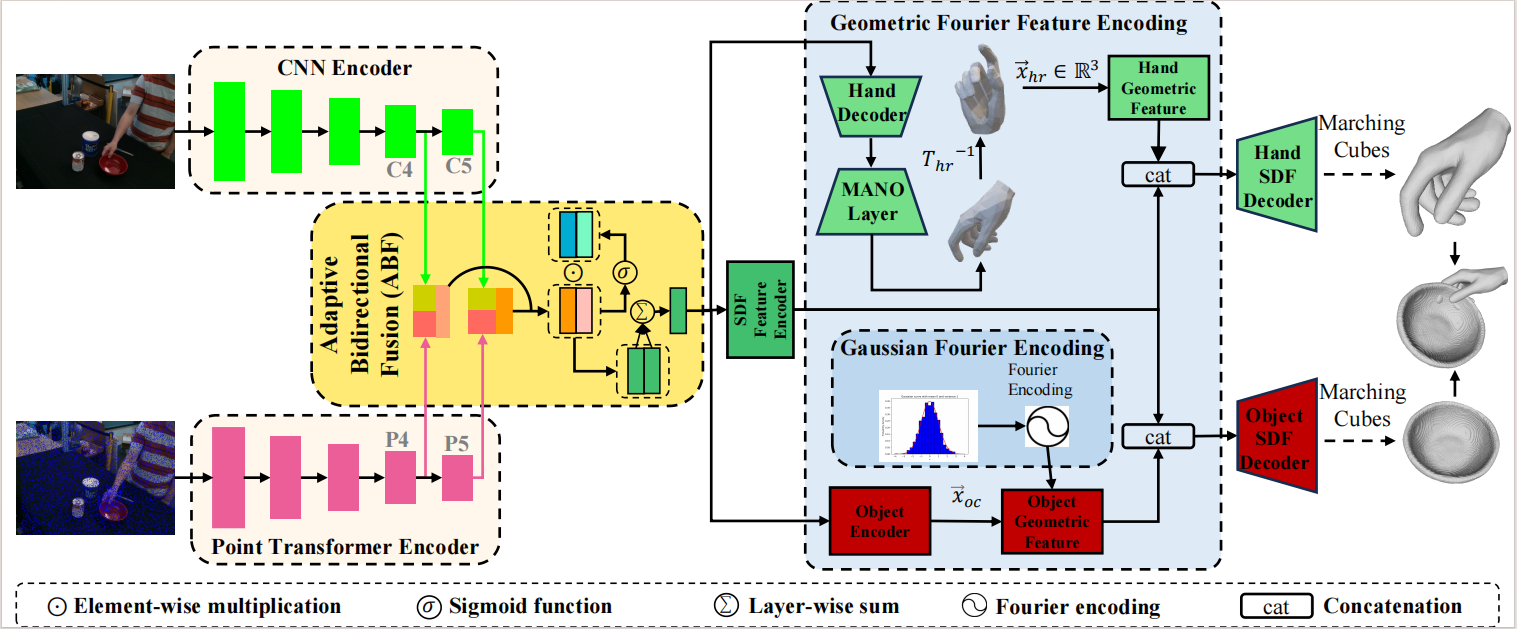
Our method. Architecture of the proposed model. The proposed method includes four modules: a two-stream RGB-point cloud encoder (TSRPE), an adaptive bidirectional fusion (ABF), a geometric Fourier feature encoding (GFFE) and a hand-object SDF decoder (HODecoder).
Acknowledgements
Research supported by the National Natural Science Foundation of China under Grant 62088101, Grant U2013602; in part by the Shanghai Municipal Science and Technology Major Project under Grant 2021SHZDZX0100; in part by the Shanghai Municipal Commission of Science and Technology Project under Grant 22ZR1467100, Grant 22QA1408500; in part by the Fundamental Research Funds for the Central Universities under Grant 0200121005/174.
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.
The template for this webpage is from Shizhe Chen. Some functions used to build the interactive 3D demo are stolen from Nilesh Kulkarni's great work.